スケーラビリティと信頼性のためのOneLoginの設計 - パート1:ログインクラスター
2021年9月2日 | Tomas Soukup | 製品とテクノロジー
前回のブログ記事では、OneLoginにとって信頼性がいかに重要であるか、そしてそれをどのように測定しているかをご紹介しました。
今回のブログ記事「スケーラビリティと信頼性のためのOneLoginの設計」では、信頼性とスケーラビリティの高い製品を実現するために、私たちがどのようにOneLoginを設計したかをご紹介していきます。
OneLoginは約10年前にスタートしました。スタートアップ時の成長過程で、多くのヒストリカルなお荷物、設計が不十分な(または全く設計されていない)コンポーネント、多くのボトルネック、「レガシー」なインフラなど、一般的に会社が成長し、雇用が加速し、管理が不足したときに形成されるものを構築しました。
1年半ほど前、私たちは信頼性と信頼性とスケーラビリティに焦点を当てた「Hydra」イニシアチブを立ち上げ、さらに「Hydra Cloud Infrastructure」の大規模な再設計プロジェクトを開始しました。
目標
優れた製品設計や再設計は、目標から始まります。目標は、新しいデザインは何を満たすべきか、さらに重要なこととして、ソリューションの過剰設計を避けるために、何が必要でないかを把握するために重要です。
私たちの目標は次のとおりです。
- エンドユーザーに99.999%(ファイブナイン)の一貫した信頼性を提供する
- すべての主要な認証フローにおいて、現在の「通常」の100倍のスループットを実現する
メモ:
信頼性の定義と測定方法については、前回のブログ記事をご参照ください。
OneLoginでは、1秒間に数千件のリクエストを処理しています。
主な原則と制約
OneLogin Hydra Cloud Infrastructureの設計を始める前に、私たちは新しいアーキテクチャの主な原則と、必要とする制約条件をいくつか定義しました。
セキュリティが第一 - ソフトウェアシステムの設計は多くのトレードオフが含まれています。私たちはセキュリティを犠牲にしたくありません。
信頼性は重要な機能 - 高い信頼性は単なる非機能要件の一つではありません。我々のプラットフォームの重要な機能であり、差別化要因でもあります。
製品よりもプラットフォーム - IdaaSは歴史的に製品やサービスとして認識されてきましたが、私たちは最終的に大規模なアイデンティティプラットフォームを構築します。
単一障害点の排除 - エンドユーザーフローの経路上にあるアーキテクチャのどのレイヤーにも、単一障害点(またはコンポーネント)があってはなりません。
マスターまたはレプリカDBストレージ - Postgresが主なDBストアであり、これを他のものに置き換えることは現実的ではありません。Postgresのマスタースレーブモデルのような制約を用います。
コードとしてのイミュータブルインフラストラクチャ - すべてのインフラはコードで完全に記述され、Gitに保管されています。すべてのプロセスは自動化されており、オペレーターによる手動の変更(Click-Ops)やペットはありません。すべてのデプロイされたアーティファクト(サーバー、サービスなど)はイミュータブル(不変)です
キーインサイト
最新のサイトの信頼性とスケーラビリティ技術は、万能のソリューションを提供するものではありません。サービスやシステムの種類によって、アプローチは異なります。重要なのは、問題を解決するために必要な要素を見つけ、それを用いることです。
以下は、OneLoginを運用してきた経験から、OneLogin Hydra Cloud Infrastructureの意思決定、トレードオフ、そして最終的な設計において重要な要素となったキーインサイトです。
テナントは相互に接続されていない
当社のテナント(顧客企業)は相互に接続されていません。データを共有することも、相互に作用することもありません。
本製品は、基礎となるリソースをより効率的に使用するためにマルチテナントとして設計されています。しかし、より高いスケーラビリティ、独立性、セキュリティ、異なるコンプライアンス要件、低レイテンシーを達成するために、テナントを自由に分離することができます。
アドミニストレーションとエンドユーザーのオペレーションは大きく異なり、本質的に独立している
オペレーションには大きく分けて3つのグループがあります。
- エンドユーザーのアクション - 主にユーザーがサードパーティのアプリケーションにサインインするために認証を行う
- 管理タスク - 主に製品の設定を行う
- バッチおよびジョブ処理 - 管理操作やユーザー同期などのスケジュールされたイベントのため、大量の計算や時間を要する処理をバックグラウンドで実行する必要がある
これら3つのオペレーションでは、異なるレベルのSLA、重要性、スケール要件、対象者などが含まれます。
エンドユーザーのログインは、私たちにとって最も重要な機能であり、基本的に読み取り専用の操作です
OneLoginの主な機能は、エンドユーザーのログインです。
エンドユーザーログインとは、OneLogin UX、サポートされているプロトコル、またはAPIを通じて、OneLoginへのアクセス、OneLoginへの認証、OneLoginを介したアプリへの認証またはアクセスを試みるエンドユーザーに代わって、OneLoginにリクエストすることです
エンドユーザーのログインは、ほとんどの場合、(サブセットの)データを読み取るリードオンリーの操作ですが、それらを書き込む必要はほとんどありません。
補完的なエンドユーザーログイン操作は迅速に行なわれる必要がありますが、ただちに行う必要はありません
エンドユーザーログインには、サービスが完全に機能するために多くの補完的な操作が含まれています。これらの操作は迅速に行われる必要がありますが、必ずしもただちにまたは同期して行われる必要はありません。
デプロイメントについて一言
次のセクションに移る前に、私たちのオペレーションについて少し説明します。
OneLoginは、マルチテナント型の製品として設計されています。Amazon Web Services(AWS)のクラウドコンピューティングプラットフォーム上に展開され、シャードに分割されています。各シャードは数万人のお客様に対応しています。シャードは最も高いレベルで分離されています。独立したデータストレージを持ち、完全に独立し分離され展開されています。
現在、EUシャードとUSシャードの2つのシャードがあり、FedRampでの使用を目的とした政府シャードの構築を進めています。
各シャードには、複数のアクティブなAWSリージョンに配置されています(単一障害点はありません)。
各リージョンでは、プラットフォームのすべてのサービスが、複数のアベイラビリティーゾーンに均等に分散されています。
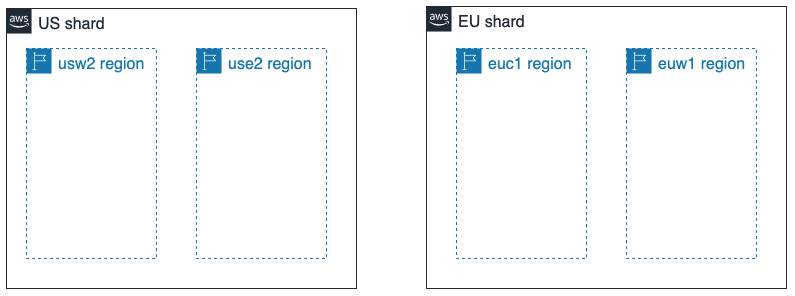
図 - シャードとリージョン
少し寄り道をしました。本題に戻りましょう。
ログインと管理者の操作
原理原則、目標、キーインサイトをまとめると、信頼性、スケーラビリティ、使用方法などの目的や要件が異なる、異なる対象者を含む、主に2つの層を扱っていることが明らかになりました。この2つの層をそれぞれ独立して運用することが可能だと思われました。
私たちはそれらを、「ログイン」と「アドミン」と呼ぶことにしました。
- ログイン では、エンドユーザーによるサードパーティアプリへのサインインを処理します。
- アドミンは、OneLoginアカウントを設定したり、アカウントディレクトリやサードパーティアプリとのバックグラウンド同期ジョブを実行したりします。
主な違いをまとめてると、以下の通りになります。
ログイン
- 対象者:エンドユーザー
- 高いスケーラビリティ、低遅延、期待される即応性
- 信頼性が重要
- ほとんどが読み取り専用の操作 - フローが設定されると、ログインはほとんどが読み取り操作となり、多少の副作用が伴う
アドミン
- 対象者:管理者
- 同期トラフィックが非常に少ない(製品を設定する管理者)
- 非同期のジョブが非常に多い(ディレクトリの同期やサードパーティのswプロビジョニング)
- 書き込み操作が多い
これは、私たちが必要とするスケーラビリティと信頼性のレベルを達成するための重要なデザイン方式でした。
DBのトポロジーがマスター・スレーブであることを考えると、(マスターDBが単一障害点であり、フェイルオーバーが瞬時に行われないため)書き込み処理でファイブナインの信頼性を得ることや、非常に高いスケーラビリティを実現することは非常に難しい(あるいは不可能)でしょう。しかし、ログイン操作を完全に分離すると、(ログイン操作はほとんどが読み取り専用であることを認識した上で)読み取り専用のレプリカ(またはその他のバックエンドのリソース)を「無制限に」割り当てることができ、極めて高い信頼性とスケーラビリティを実現することができます。
アドミンの部分は、まだいくつかの重要な限定されたリソース(マスターDBなど)に依存しています。しかし、その部分にはそのような極端に高い信頼性の要求は必要ありません。また、操作は大部分が非同期で行えるため、必要なレベルまでのスケールアップが非常に容易です。
私たちは、ファイブナインの信頼性を得るという目標(そして私たちが最も重視していること)を、最も重要な機能であるログイン層に適用することにしました。アドミン層にも十分な信頼性が必要ですが、この分野では、ログインとジョブのすべての操作に対応できるようにスケーリングすることに主眼を置いています。
そうして、私たちはクラスターの設計を始めました。
クラスター
クラスタ ーとは、専用の機能を持つステートレスな(マイクロ)サービスのバンドルセットです。現在、2種類のクラスターがあります。
- ログインクラスター - エンドユーザーのフローを処理
- アドミンクラスター - アドミンタスクとジョブ処理
アドミンクラスターとプライマリ領域
アドミンクラスターとログインクラスターは、主にマスター・スレーブDBアーキテクチャに従っています。
常に各シャード内の1つのリージョンがプライマリです。他のリージョンはセカンダリです。
プライマリリージョンには、アクティブなアドミンクラスターとマスター(読み書き可能な)Postgresデータベースがあります。
管理クラスターでは、管理タスク、イベント、バッチジョブ処理などの書き込み操作が処理され、操作結果がマスターデータベースに保存されます。
ログインクラスターとセカンダリリージョン
これで、ログインクラスターの設計を始めるための情報が揃いました。
プライマリではないリージョンは、セカンダリリージョンと呼ばれます。セカンダリリージョンには、読み取り専用のデータベースレプリカのみが含まれます(マスターデータベースは含まれません)。
エンドユーザーのフローは、ログインクラスターにルーティングされ、処理されます。エッジプロキシでは、ログイン層とアドミン層を決定する一連のルールを設定します。
ログインクラスターは、プライマリとセカンダリの両方のリージョンに配置されているため、スケーラビリティと信頼性が向上し、エンドユーザーのオペレーションをユーザーに近づけることができます。ログインクラスターはアドミンクラスターから完全に切り離され、隔離されています(プライマリリージョンであっても、それぞれのレプリカから読み取っています)。これにより、アドミンクラスターでの障害がエンドユーザーに影響を与えることを確実に妨げることができます。
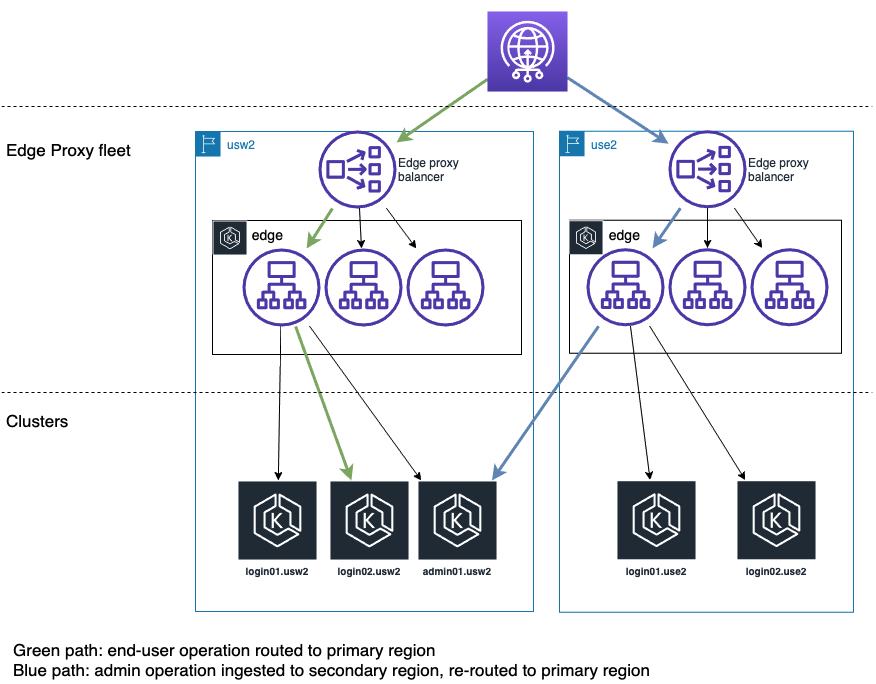
図 - エッジプロキシからクラスターへのルーティング
ログインクラスター:信頼性
ログインクラスターは、地域および地域間のアクティブ・アクティブな冗長性を備えています。
- 各リージョンには2つのログインクラスターがあります。リージョン内の両方のログインクラスターがアクティブで、通常の状態ではリージョン内のトラフィックを半々で分割します。
- すべてのリージョン(プライマリリージョンを含む)にはログインクラスターがあり、最も近いエンドユーザーからのトラフィックを受け取ります(最も近いリージョンへのレイテンシーベースのルーティングを使用しています)。
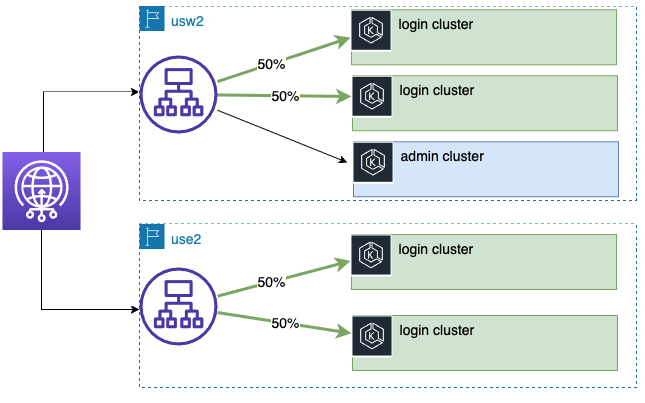
図 - ログインクラスター間の半々のトラフィック分割
この設計により、トラフィックの一部をリダイレクトする、または、不健全なクラスター(リージョン内)やリージョン全体から完全なフェイルオーバーを実行することができます。
クラスターフェイルオーバー
エッジプロキシは、クラスター内で実行されている各サービスに対してサービス固有のバックエンドを登録します。1つのログインクラスター内のサービスのいずれかが不健全であると検出された場合、トラフィックは地域内の2つ目のログインクラスター内の健全なバックエンドに完全に切り替えられます。
クラスターフェイルオーバーは、通常はオペレーターの明示的な操作としてログインクラスター全体に対して実行することもでき、その結果、特定の地域のすべてのユーザートラフィックを利用可能なログインクラスターの1つのみに送ることができます。
完全なフェイルオーバーの前に、ターゲットクラスターが過負荷にならないように、ターゲットクラスターを現在の容量にスケールアップするためのチェックが行われます。
図 - 不健全なログインクラスターのフェイルオーバー
リージョンフェイルオーバー
同じ部分的または完全なフェイルオーバーをリージョン全体で実行することができます!
リージョン全体のフェイルオーバーは、通常、インシデントの緩和または復旧措置として実行されます。リージョンフェイルオーバー時には、まず対象となるリージョンの容量がチェックされ、追加された負荷を処理するためにスケールアップされます。その後、新しいリクエストがフェイルオーバーリージョンにルーティングされます。
AWS Global AcceleratorとAWS Global networkを使用して、ユーザーのリクエストを最も近いリージョンにルーティングします。Global Acceleratorにより、トラフィックを整形し、不健全なリージョンからトラフィックの一部または全部をリダイレクトすることができます。
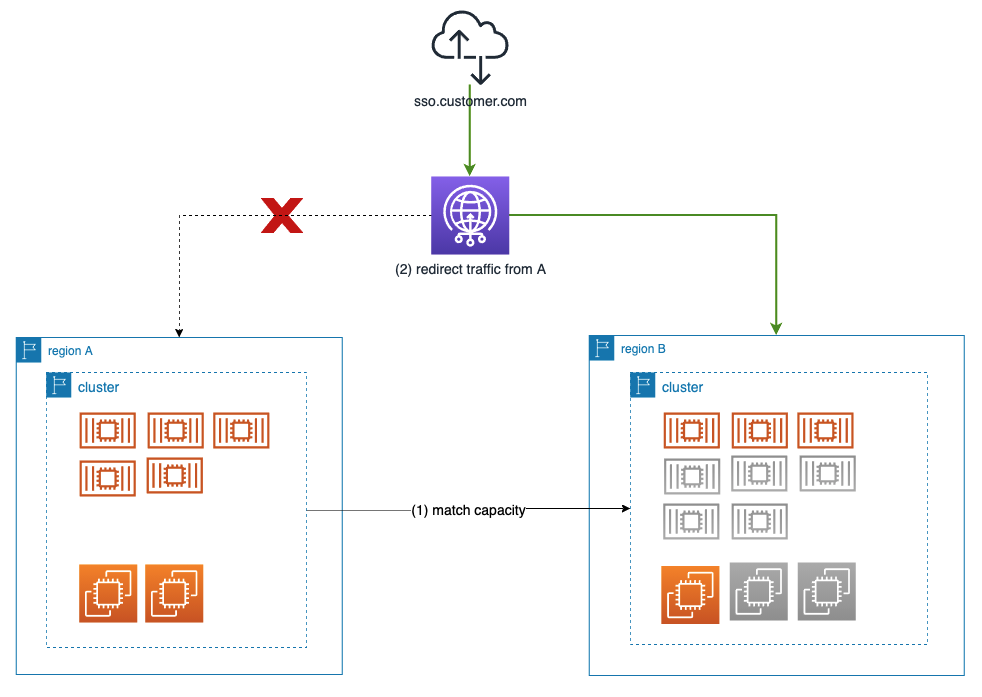
図 - 事前の容量調整によるリージョンフェイルオーバー
ログインクラスターからのデータ書き込み
各ログインクラスターは、3つの読み取り専用のデータベースレプリカに接続されています。すべてのログインサービスは、読み取り・書き込み可能な(マスター)データベースに直接アクセスせずに操作することができます。エンドログインフロー中のほとんどの操作はリードオンリーですが、すべてではありません。ログインクラスターから書き込み操作を実行する方法はいくつかあります。
- 操作はキューに入れられ、メッセージブローカー経由で管理クラスターに送られ、そこでジョブワーカーによって処理され、マスターDBに保存されます。その後、DBレプリケーション(マスターDBからレプリカへ)により、すべてのリージョン(およびクラスタ)のレプリカDBに更新情報が配信されます。
- 一部のケース(ハイスケール処理のサブセットや非関係リレーショナルデータの場合)では、グローバルテーブルを持つAWS DynamoDBを活用しています。セカンダリリージョンのDynamoDBにオペレーションが書き込まれ、グローバルテーブルにより他のすべてのリージョンに配信されます
- サブセットのオペレーションでは、リージョン・ローカルのストアのみが必要となります。その場合(通常は)、AWS Elasticacheを活用します。
- 特定の例外的なケースでは、同期的な書き込みアクションが必要になります(例えば、ログイン時にジャストインタイムでユーザーを作成するなど)。その場合、コールは外部から実行されたかのようにルーティングされ(「東西」ではなく「南北」のコールとして)、インフラのすべてのルーティング層を活用します。
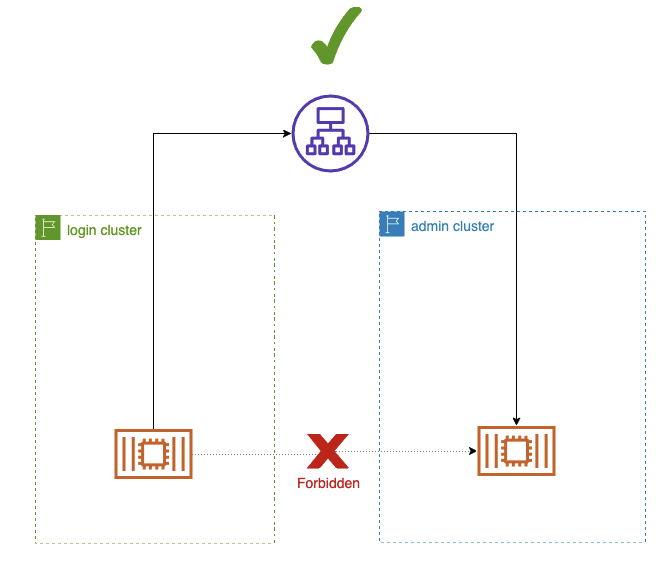
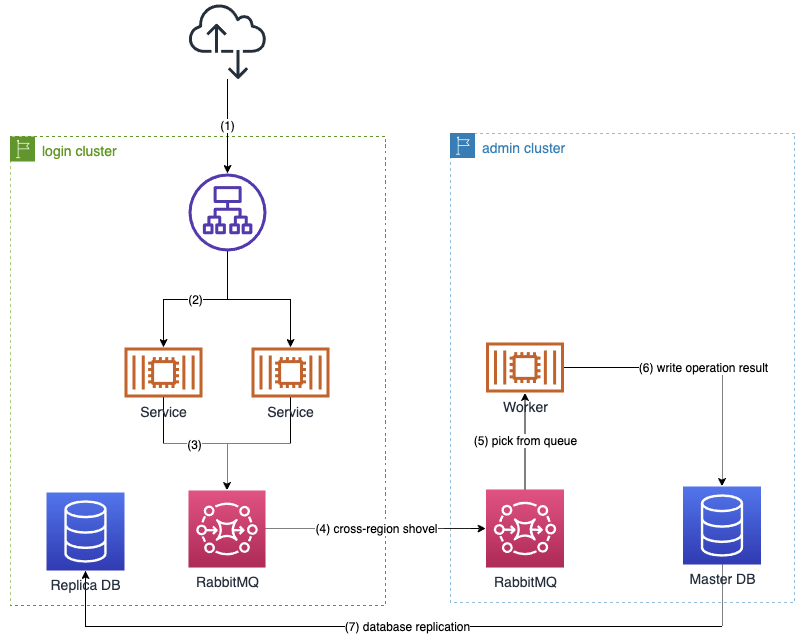
図 - 書き込み操作を非同期に処理
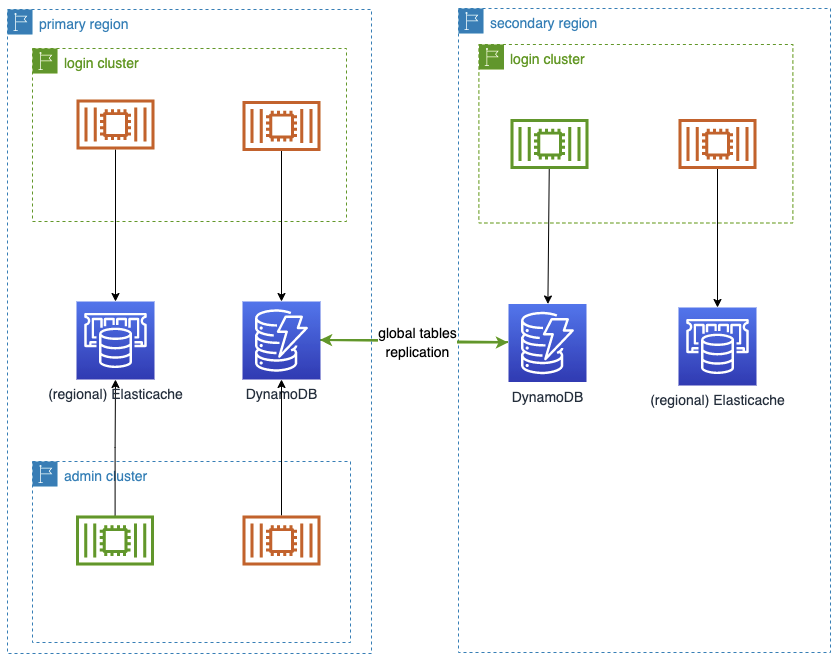
図 - DynamoDBのグローバルテーブルと(リージョナル)Elasticacheの利用
図 - クロスクラスター同期操作の実行
ログインクラスター:水平スケーラビリティ
スケーラビリティとは、システムにリソースを追加することで、増大する作業量を処理するシステムの特性です。作業負荷が急激に増加しても、効果的なパフォーマンスを維持するためにシステムを再設計する必要がない場合、そのシステムはスケーラブルであると言うことができます。
スケーラビリティを実現するには2つの戦略があります。
- 垂直スケーラビリティ(またはスケールアップ では、コンポーネントをより大きく、速くして、より多くの負荷が処理できるようにすることです。一般的な例として、1台のマシンにCPUやメモリを追加することが挙げられます。
- 水平スケーラビリティ(またはスケールアウト では、より多くのコンポーネントをシステムに追加して負荷を分散させることで問題に対処します。言い換えると、リソースのプールに「マシン」を追加することです。
ログインクラスター(およびOneLogin Hydraインフラ全体)は、完全な水平スケーラビリティのために設計されています。複数のアーキテクチャレベルでスケールアウトし、このコンセプトをさらに推し進めることができます。
- クラスター内のノードリソースのスケールアウト -
EC2インスタンス、サービス、プロキシ、データベースなどの様々なリソースをクラスター内に自動的に追加(または削除)します。
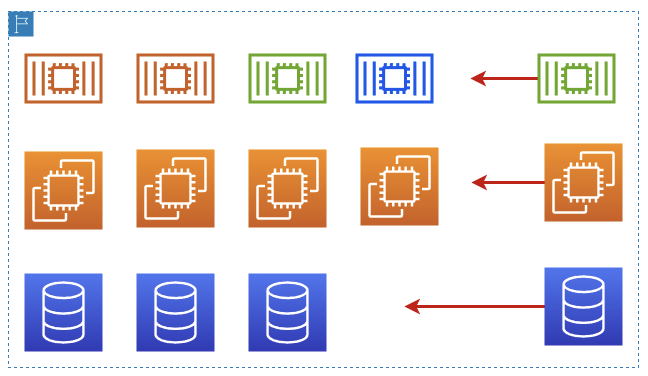
- ログインクラスター全体のスケールアウト -
ログインクラスターの設計により、クラスターは完全に独立していますが、全体システムには接続されています。そのため、ログインクラスターの設計を活用して、クラスター全体のレベルでスケールアウトすることができます。スケールアウトしたクラスターは、同じリージョンに展開することも、まったく別の(新しい)リージョンに展開することもできます。
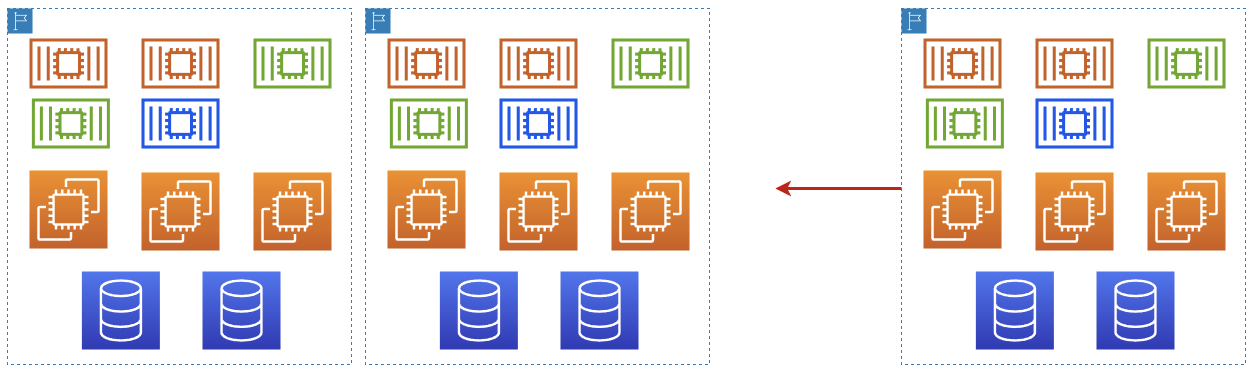
- ログインクラスター全体のスケールアウト -
ログインクラスターの設計により、クラスターは完全に独立していますが、全体システムには接続されています。そのため、ログインクラスターの設計を活用して、クラスター全体のレベルでスケールアウトすることができます。スケールアウトしたクラスターは、同じリージョンに展開することも、まったく別の(新しい)リージョンに展開することもできます。
この追加されたスケールアウトクラスターデザインは、1つのクラスターで数千のノードにスケールアウトする際に課される可能性のある制限にも対処します。さらに、このログインクラスターは、それぞれが他のクラスターから負荷を受けたり、クラスター間でトラフィックを再分配したりすることができるため、信頼性と耐障害性を高めることができます。
マルチテナントの設計と組み合わせることで、どのログインクラスターからでも、どのテナントに対しても「無制限」のリソースを効率的に提供することができます。
ここで示されたシステムにより、大規模かつ効率的でメンテナンス性に優れたIDaaSプラットフォームを実現することができますが、最上位のシャーディングを分離することで、スケールアウトを活用することもできます。各シャードは完全に独立し隔離されているため、新しいシャードを追加することで、理論的には任意の数のテナントにスケールアウトすることができます。
クラスターのアーキテクチャ
クラスターは、スタンドアロンのKubernetes(AWS EKS)クラスターとして実装されています。
そのアーキテクチャ、デザイン、展開は複雑であるため、ブログ記事でより深く説明する価値があります。
まとめ
スケーラビリティと信頼性のためのシステム設計には複数の方法があり、その他と同様に唯一の方法はありません。
自分たちの製品がどのように使われているかを調べ、主なユーザーを分類し、何に重点を置くべきか、(もしかしたらさらに重要かもしれない)何に重点を置かないかを決めることで、将来のソリューションのキーコンセプトが見えてきました。
そのコンセプトを書き出し、その道のりに沿って一つ一つ設計上の決定を行った結果、スケーラブルで信頼性の高い製品を構築することができ、私たちはそれをとても誇りに思っています(信頼性への道のりを参照)。
自分の製品がどのように使われているかを見て、自分なりのキープリンシプル、制約そしてインサイトを見つけてください。このブログが、その道のりの手助けとなれば幸いです!