信頼性の測定方法
2021年8月25日 | Tomas Soukup | 製品とテクノロジー
信頼性
ビジネスSaaSのサービス(製品)が利用できなくなると、ビジネスに影響が出ます。サービスによってはそれほど深刻なことではないかもしれませんが(最近のレシートの入力や処理ができず、少し待つことになるかもしれません)、他のサービスでは、重大な事態(メールの受送信ができなくなる)となり得ます。
私たちの業界では、「アイデンティティ&アクセスマネジメント」と呼ばれる製品を会社などの機関に販売し、その機関はそれを設定・カスタマイズして、エンドユーザーに展開します。これらのエンドユーザーは、自分たちのすべてのビジネスアプリにアクセスするために当社の製品を使用しています。私たちは、お客様のオフィススイート、人事システム、CRMソリューションなど、あらゆるものへのゲートウェイなのです。また、私たちはZoomやSlackへのアクセスを提供しているだけではなく、小売店のPOSシステム、製造業の現場、患者のケアや調剤を行う医療システムなどのアプリへのアクセスも提供しています。
エンドユーザーがこれらのシステムにアクセスできなくなった場合、お客様のすべての従業員、特に社長が(同様にアプリにアクセスができないため)そのことに気付くことでしょう。お客様の社内のヘルプデスクが対応し始めます。自分たちのインシデントレスポンスチームを立ち上げます(時おり夜中に人々を起こすことにもなります)。それはとても深刻な問題なのです。お客様のビジネスに深刻な影響を与え、時には運営を停止させてしまうこともあります。それは、私たちの評判やお客様との関係に影響を与えます。
そのため、OneLoginでは信頼性を製品の2番目に重要な「機能」としています(セキュリティが1番目に重要です)。私たちは全員が非常に高い信頼性を達成することに専念しており、組織全体がこの目標に向かっています。
しかし、「この目標」とは実際何を示しているのでしょうか。
まず、一つのストーリーからご紹介します。
これは皆さんがすでにご存知のストーリーです。
会社が立ち上がりました。製品が発売されました。
そして成長していきます。成長の速度が速くなっていきます。
製品とコードは成長しているものの、管理が不足しています。
すべてがナチュラルで、まとまりがなく、「スタートアップ的」です。
デザインの歯車がきしむようになります。バグのない状態でリリースするのがさらに難しくなります。
ユーザー数の増加に伴い、システムに負荷がかかるようになります。
ランダムに不具合が発生するようになります。
マネージャー達は、「プロセス」、「管理」、「非機能要件」について話し始めます。
エンジニア達は、「技術的負債」、「レガシー」、「再設計」、「リライト」について述べるようになります。
私は同じようなストーリーを、成功しているすべての企業で見てきました。
では何をすべきでしょうか。
すべてリライトすべきでしょうか。:-)
改善しましょう
わかりました、リライトはしません。繰り返し改善していく必要があります。しかし、
ピーターは賢い人でした。私よりはるかに賢い人でした。
では、何をどのように測定するか分かるまで、改善することはできません。。。
指標
信頼性を測定しましょう!
周りにある全てを測定し、目標を定めたくなるかもしれませんが、それは良いアイデアではありません。それにより、最も重要な指標や目標がぼやけてしまい、リソースが希薄になり、分析により麻痺状態に陥ってしまうことでしょう。
私たちの目標は、私たちが提供しているサービスの品質に対するお客様の見方を最もよく表す、一つの客観的な指標を考え出すことでした。結果は以下の通りです。
一つの指標:エンドユーザーのログイン成功
定義:エンドユーザーが、OneLoginにサインイン、または、OneLoginを介してサードパーティのアプリにサインインすることができる。
詳細:これは、エンドユーザーのログイン成功を含む、重要な信頼性指標です。これには、OneLogin UX、サポートされているプロトコル、またはAPIを介しているかどうかにかかわらず、OneLoginへのアクセス、OneLoginへの認証、またはOneLoginを介したアプリへの認証やアクセスを試みるエンドユーザーに代わり、OneLoginに対するすべてのリクエストが含まれます。
メモ:私たちの製品は、アプリにアクセスするエンドユーザーをサポートすること以外にも、様々な機能を持っています。私たちには、製品の設定、管理、監視に使用する大規模な管理コンソールがあります。ディレクトリの同期やアプリのユーザープロビジョニングなど、継続的に実行している管理タスクが多くあります。これら他の機能も重要ですが、リアルタイムに行われるエンドユーザーのアクセスほど機密性や重要性は高くありません。
どのように
私たちは、HTTPレスポンスコードを測定し、2つに分類することにしました。
- 失敗 - 500(Internal Server Error)、502(Bad Gateway)、503(Service Unavailable)、504(Gateway Timeout)などすべての50-応答コード
- 成功 - その他すべて
指標は、成功したエンドユーザーリクエスト数(50-以外のコード)を、すべてのエンドユーザーリクエスト数(測定ウィンドウ内)で割ったものです。

これは比較的シンプルですが、エンドユーザーの体験に近いものです。
2番目のステップは、指標となるデータをどこで入手するかを決定することでした。
ここで3つのアプローチを検討しました。
- e2e-monitorからデータを収集(e2e-monitorは90秒ごとに、すべてのOneLoginリージョンに対してすべての主要なユースケースを実行する、エンドツーエンドのテストスイートを実行します。)
- フロントエンドサービスからのデータを収集(「フロントエンド」サービスは、私たちのインフラ外からのリクエストを取り込むサービスです)
- エッジプロキシからデータを収集
e2e-monitorのアプローチの利点は、テストスイートがエンドユーザーの視点で認識されるため、エンドユーザーの体験を完全に反映できることです(ブラウザコードのバグやブラウザの再試行なども含まれます)。一方で、すべてのユースケースをテストでカバーしたとしても、テストの対象となるのはリクエストのごく一部であり、必要とする精度を得ることはできないでしょう。
フロントエンドサービスは、各リクエスト対して最も多くの情報を持ち、ユーザーやアカウントについての詳細を追加、または、ログイン・フロー全体を関連付けることができます。しかし、その実施(または必要な更新)は多くのサービスにまたがるため、さらなる作業が必要となります。また、プロキシとフロントエンド間の接続性やルーティングの問題も検出できません。
そのため、私たちはエッジプロキシによる方法を採用することにしました。すべてのデータが1つのサービス(プロキシ)から送られ、それぞれのリクエストに関する情報は、私たちの目的に十分であると思われました。
3番目のステップでは、「エンドユーザー」のトラフィックをどのように絞り込み、相関させるかを決めました。エンドユーザーが使用するエンドポイント(およびパス)の定義から始め、すべてのエンドユーザーのインタラクションを非常によく表現できるまで、httpメソッド、エンドポイント、パスの組み合わせによりそのセットの微調整を続けました。
例として、何度も繰り返し行った後の、現在(2021年6月時点)の指標計算の一部を示します。
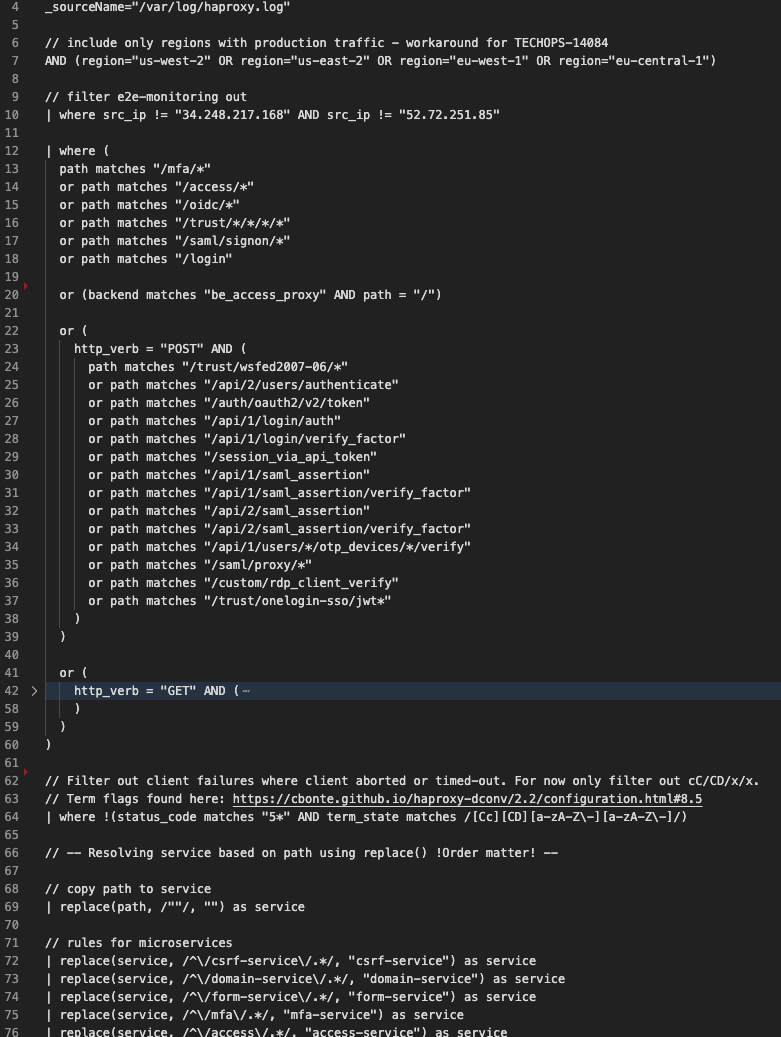
目標
最後のステップは目標を定める事でした。
最終的には99.999%(ファイブナイン)の信頼性を実現したいと思いましたが、この取り組みを始めた2020年1月の時点では、それは空想のようなものでした。
そこで、まずは2020年末までに99.99%(フォーナイン)を達成することにしました。これも非常に野心的な目標でした。
また、月に一度、CEOとのレビューミーティングを設けました(幸運なことに、私たちのCEOは、優れた技術が顧客満足度やビジネス全体の原動力となることを確信しています)。そのミーティングでは、これまでの実績や課題、目標に向けての改善点などを報告しました。
旅程
ではどのように実際になされたのでしょうか。
最初の試み
これは2020年1月のレビューでのスクリーンショットです。

初期の指標と初期のエンドポイントのセットを定義したところです。ダッシュボードがなかったので、エッジプロキシのログを調べ、いくつかのクエリを実行し、Googleスプレッドシートを使って12月と1月(前月比)のデータを手動で計算して、自動化すべきことや現在の数値を理解しました。
最初のダッシュボード
2020年2月に最初のダッシュボードを入手しました。引き続き、「エンドユーザーフロー」の範囲を微調整し、指標の測定をシャード(米国とEUのシャード)ごとだけでなく、最初の2つの主要なサービスに特化して行い、サービスの所有者に具体的な報告を開始しました。
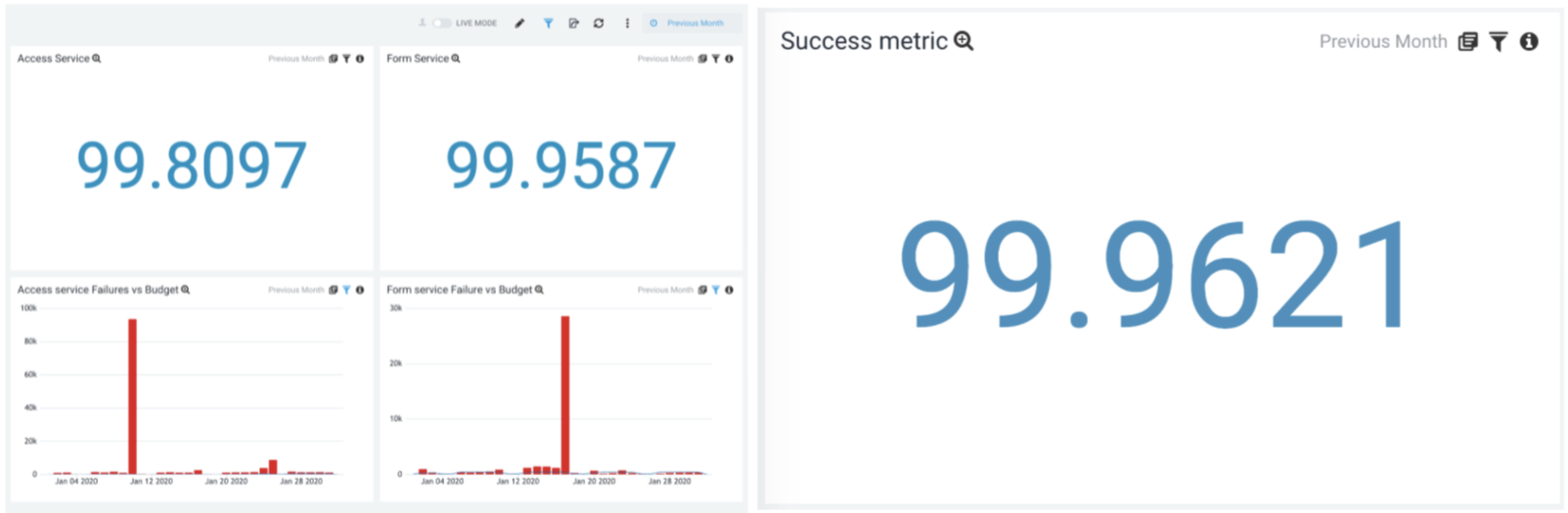
豆知識:この初期のダッシュボードは、更新の際、30日分のデータを計算するのに2、3時間かかっていました :-)。しかし私たちは、何かを手にしたのです!
エラーバジェットの導入
2020年3月に、「Google Site Reliability Engineering(SRE)」に掲載されている「エラーバジェット」の概念を導入し、必要な改善点を明確に伝え、プラットフォーム(SRE)チームと製品開発の間で共通のインセンティブを持ち、イノベーションと信頼性のバランスを取ることを目指しました。


スクリーンショットに示されているように、私たちは各インシデントの新しい指標の効果も計算し始めました。
99.99%という最終目標はまだ遠いので、より小さな目標を定め、赤、黄、緑のしきい値を定義して、反復的な目標の達成状況を示すようにしました。グリーンに到達したら、次の目標を設定しました。.
クライマックス
7月下旬、私たちは転機を迎えました。どんなに努力しても、数字は上がりませんでした。
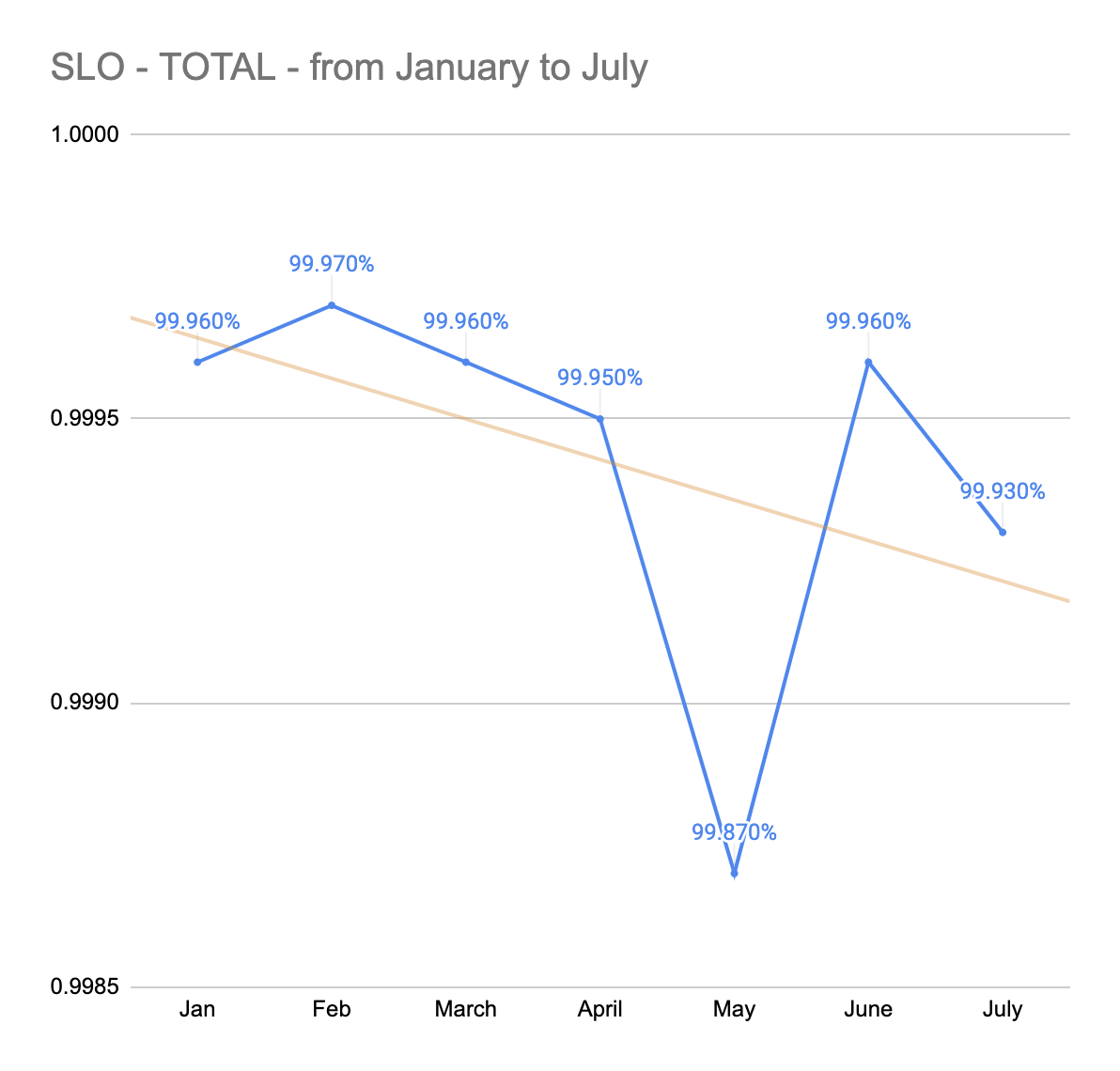
主観的には、良くなっている、と感じていても、数字を見るとそうではないのです。それには大きく分けて2つの理由がありました。
- 測定指標の微調整を続け、UDPベースのRadiusのような適切なデータを得るのが難しい非標準的なサービスを追加し続けましたが、新しいエンドポイントやサービスのパフォーマンスは悪化し、それらを含めることで数値が悪化してしまいました。
- 5月と7月には深刻な信頼性インシデントが発生しました。
雰囲気も芳しくなく、目標は不可能に思えました。加えて、コロナ渦の状況も事態を好転させるものではありませんでした。
レッドゾーンプロジェクト
満足のいく結果が得られなかったため、8月の初めに「レッドゾーン」プロジェクトを立ち上げました。これは、エンジニアリング全体で集中的に必要な信頼性を高める作業を行うものです。セキュリティのバグや改善を除く他のすべての作業を延期(または優先順位を下げて)し、信頼性を向上させることに全面的に取り組みました。
全員が行動を起こし、通常のオペレーションに戻る前に行わなければならない信頼性を向上する作業の範囲を定義しました。プラットフォームとSREチームは、すべての詳細事項とエンジニアリングタスクの優先順位付けを行う作業を、一時的に主導しました
重点的に取り組んだ分野は以下の通りです。
- ログインクラスター - Hydraアーキテクチャの大規模な再設計の完了(ログインクラスターについては次回のブログで紹介します)
- エンドユーザーの成功 - 失敗応答コードに対処するための協調的な取り組み - 失敗を毎月30%減らす目標を設定
- CAPA - 「Corrective and Preventive Actions(是正措置および予防措置)」プロセスを導入し、信頼性インシデント後の分析および事後調査から得られたチケットを追跡したものの、修正すべき項目が積み残されていた
- オンコールサポート - すべてのサービスオーナーチームは、それぞれのサービスに対してオンコールサポートを確立
このプロジェクトは大きな成功を収めました。
当初の目標を軌道に乗せ、年末に目標を達成しただけでなく、今後のイノベーションの基礎となる、予定していたプラットフォームの大規模な再設計を完了することができました!
これがレッドゾーンプロジェクトの実績です。
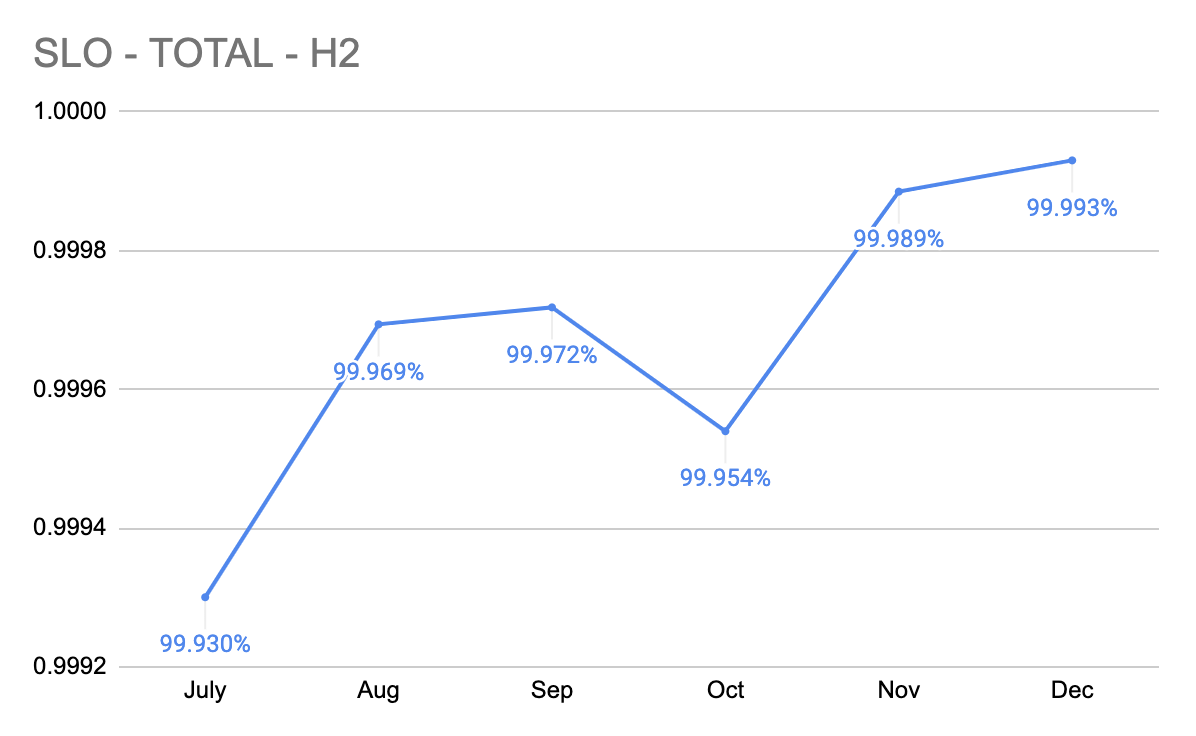
新たな目標
当社のCEOは「良い仕事への報酬は、より多くのハードな仕事をすることだ」と言っています。そこで、2020年の終わりに、2021年の新たな目標として、第1四半期末までに99.995%(フォーナインファイブ)、2021年末までに99.999%(ファイブナイン)を達成することにしました。
たった1つ「9」を加えることは大したことではないように思えますが、それは10倍の改善を意味します。桁違いの改善には、多くの場合、これまで問題なく行っていたことが通用しなくなり、さまざまな分野で変更を加えて完全に見直す必要があることを意味します。
これまでのところ、第1四半期の目標を達成し、最終的な目標についても楽観的に考えています。課題はたくさんありますが、私はそのような興味深く困難な問題を解決するのが好きなのです!
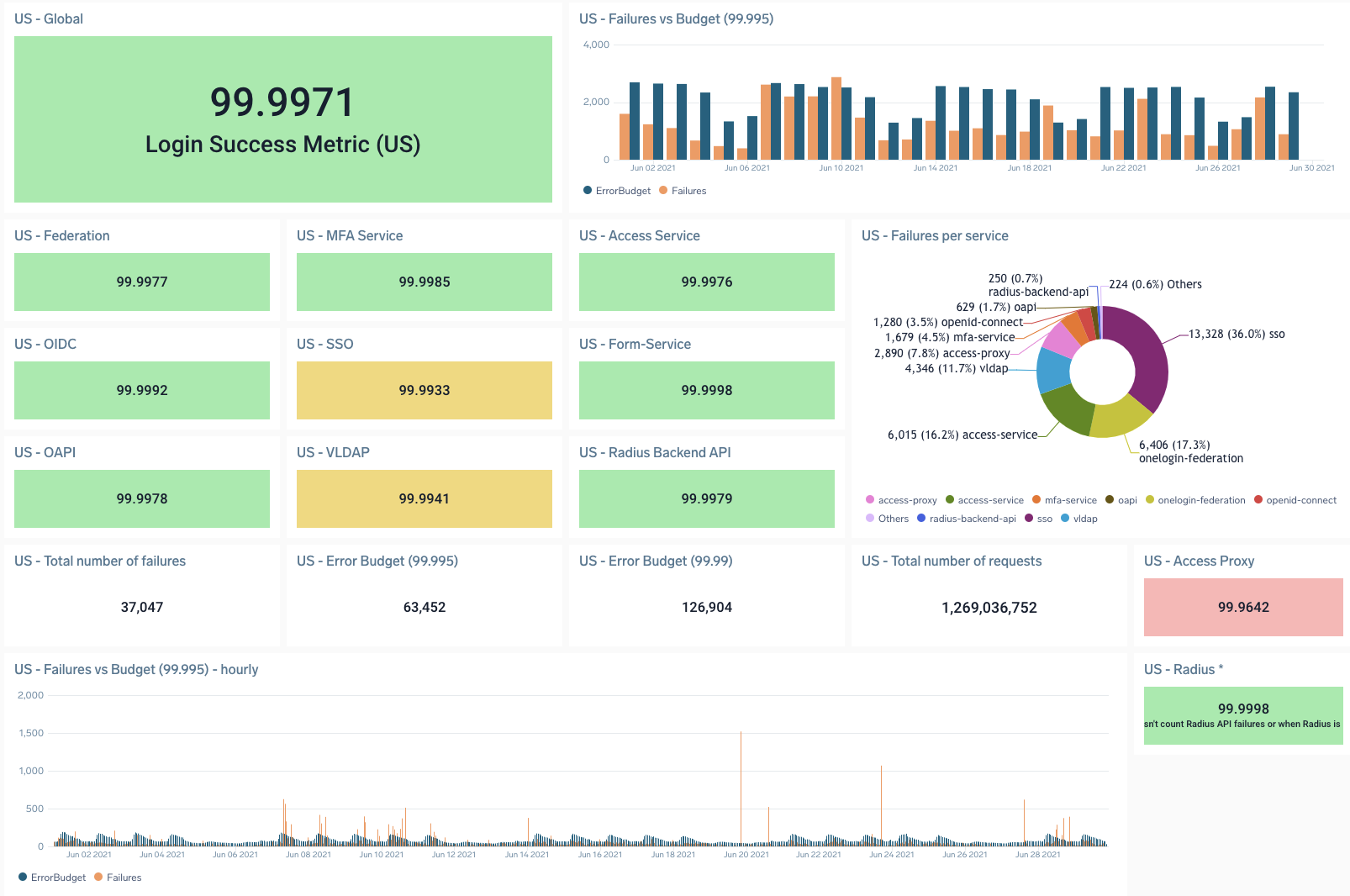
以下は最近、進化した信頼性ダッシュボードです。今後のアップデートにご期待ください。
メモ:信頼性 vs 可用性
信頼性を測定する方法は、システムが利用可能であった(=完全にダウンしていなかった)時間を総時間で割って計算する従来の可用性よりも、はるかに客観的です。これでは、トラフィックの多い時間帯(従来の可用性では月曜の朝と土曜の夜の両方が同じように計測されます)や、通常のオペレーション中のランダムな失敗リクエストは計測されません。信頼性が99.99%、99.999%、99.9999%といった高い数値になると、このような詳細事項が非常に重要になります。
私たちの経験と、過去のインシデントに関する両方の計算に基づいて、当社の信頼性SLAは、「良好な」可用性SLAよりも、ナインが一つまたは一つ半「より厳しい」ものとなっています(つまり、当社の信頼性SLAの99.99%は、従来の可用性SLAの99.995%または99.999%と実質的に同等です)。
まとめ
私たちは何を学んだのでしょうか。
指標を定義することが転機となりました。その良し悪しは問題ではありませんでした。それがスタートし、突然そして自然に話し合う内容が変わり、1つの数字に焦点が当てられ、その数字を向上させることができるようになりました。
指標の数値と追跡が具体化すると、魔法のように組織全体が目標に向かって一致しました。.小さな勝利の一つ一つが目に見え、祝うことができました。売上高はドルで表現するため、皆、理解することができます。.これは、営業部門で用いられている強力なモチベーションを、信頼性エンジニアリング(または他の分野)で応用する方法です。
最初の「おろかな」指標を導入したことで、インシデントの影響を客観的に測定したり、エンドユーザーの影響をリアルタイムでダッシュボードに表示したり、将来的に顧客ごとの健康状態をダッシュボードに表示するなど、これまで考えられなかった多くの用途や改善点を把握することができ、重要なツールや製品のイノベーションにつながりました。
複雑さや高すぎる目標に惑わされないようにしてください。些細なこと、愚かなこと、間抜けなこと、小さなこと、反復することから始めることができます。ただ、始めることが必要です。これはよく知られている真実ですが、私の意見では、まだ広く過小評価されています。